![]()
Diagnosis grouping and pairing
Once connected by means of a Web browser to Comorbidity4j (to a locally running server to to http://comorbidity.eu/comorbidity4web/) and interactively uploaded / validated the input data, Comorbidity4j web application drives the user throughout the interactive setting of the diagnosis grouping and pairing. These steps are optional and can be skipped.
- Diagnosis grouping: join multiple diagnoses into a group of diagnoses, thus considering all these diagnoses as a single one in the analysis of comorbidities;
- Diagnosis pairing: define diagnosis pairing patterns to specify / select the pairs of diagnosis to study for comorbidity.
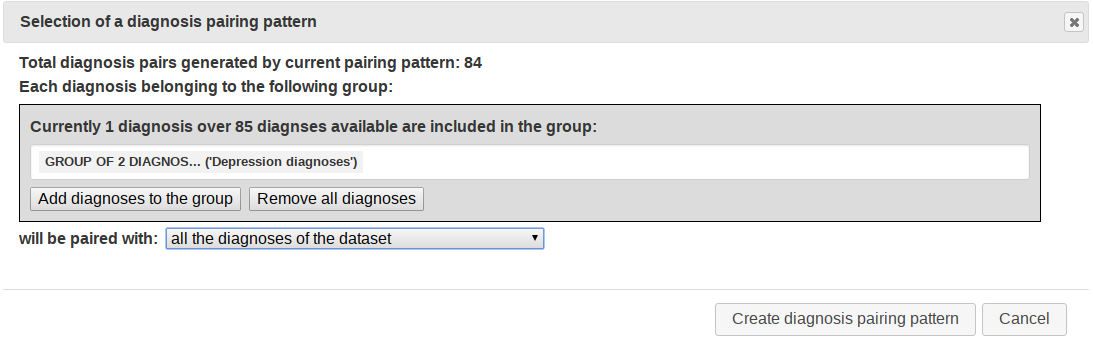
Diagnosis grouping
Join multiple diagnoses into a group of diagnoses, thus considering all these diagnoses as a single one in the analysis of comorbidities.
Grouping diagnosis codes could be useful to merge diagnosis that should be treated as a single one when executing comorbidity analysis. For instance, in this way it is possible to easily merge all the diagnosis related to different types of skin cancers into a single diagnosis named "Skin cancers". Users can interactively select the diagnoses of their dataset to join into a group by means of a several selection facilities (auto-suggest, regular expressions, etc.).
Diagnosis grouping interface (the group Depression diagnoses that includes two diagnoses has been defined):
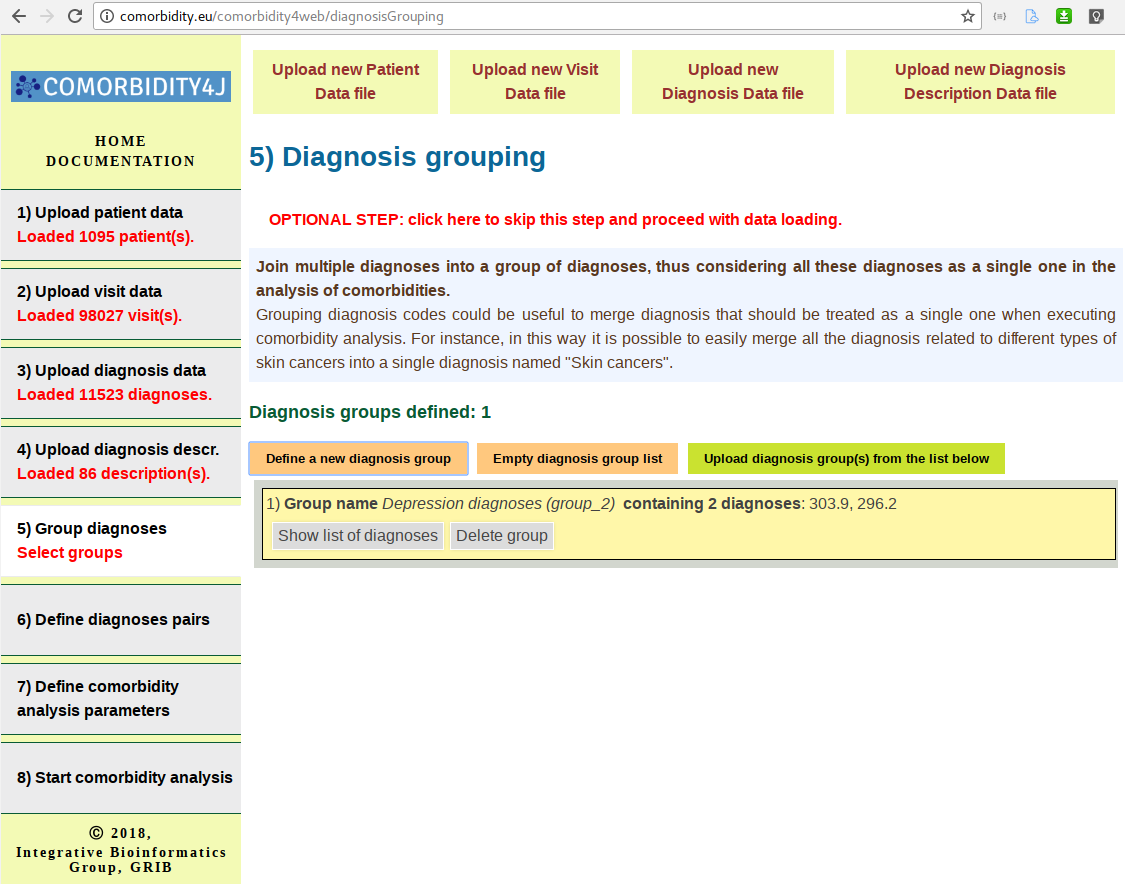
Selection of diagnosis to be joined in a group:
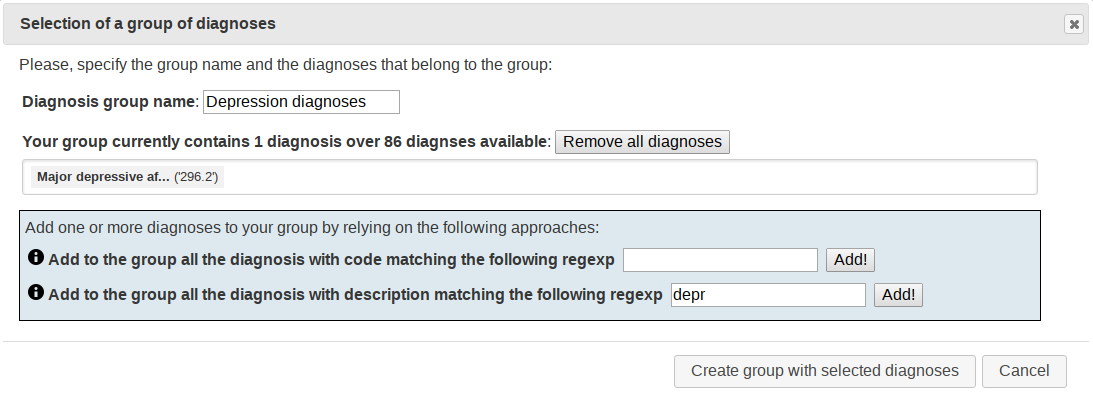
Diagnosis pairing
By default, Comorbidity4j analyzes all the pairs of diagnoses specified in your dataset to look for relevant comorbidities.
In many practical cases, users need to consider only comorbidities involving a specific set of diagnoses (diseases). By means of the diagnosis pairing interface you can interactively specify the pairs of (groups of) diagnoses you are interested to check for comorbidities by specifying for each diagnosis the set of other diagnoses it will be paired to so as to analyze comorbidity. This process is referred to as the definition of diagnosis pairing patterns. Users can select the diagnoses that will be paired by means of a several selection facilities (auto-suggest, regular expressions, etc.).
ATTENTION: if you will not define any diagnosis pairing pattern all pairs of diseases in your dataset will be analyzed to look for relevant comorbidities as default behavior. The execution time of comorbidity analysis and the RAM required is proportional to the number of diagnosis pairs that will be analyzed. We suggest to keep this number under 300,000 diagnosis pairs in order to to speed up the computation time and RAM requirements of comorbidity4j. See below to check the actual number of your analysis.
Diagnosis pairing interface (a diagnosis pairing pattern is defines, specifying that the two diagnosis of the previously created group Depression diagnoses will be paired with all the diagnoses occurring in the dataset to check for relevant comorbidities):
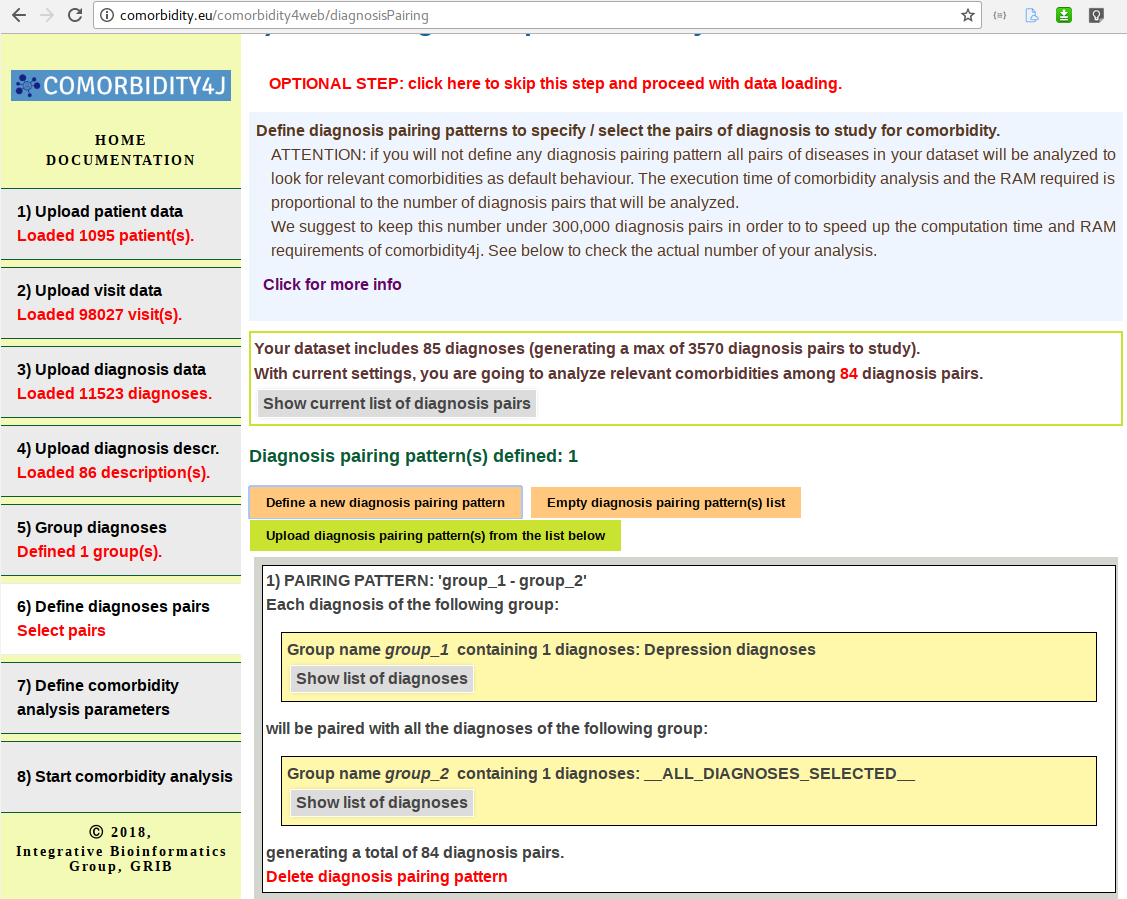
Interactive definition of a diagnosis pairing pattern: